
Published on October 14, 2022
Kubernetes controllers are becoming ubiquitous in the Kubernetes product space, in many cases the words “cloud native” can be read as “implemented as a Kubernetes controller”. Whether through large scale open-source projects like Crossplane or frameworks that allow the rapid creation of controllers and CRDs like Kubebuilder, the use of custom resources backed by controller processes has skyrocketed.
As their popularity has increased, our team at SuperOrbital has seen an increase in companies building their own custom controllers to implement product capabilities. These can be as simple as providing a Kubernetes-backed API to spin up a standardized set of Kubernetes resources for an application and as complex as managing a fleet of regionally-distributed Kafka brokers.
With this broad surface area of critical use cases integrating deeply with the Kubernetes API, teams need to ensure that their controllers work consistently and handle updates gracefully. This requires taking testing seriously from day one. We can accomplish this with a good mix of unit tests, local integration tests, and more fully featured runtime integration tests.
Controller Approaches
Kubernetes controller-runtime
Today the canonical controller implementation is the Kubernetes controller-runtime project. This project provides a set of APIs for registering a Reconciler object within a controller-manager which monitors the Kubernetes api-server and passes relevant events to the Reconciler. Both Kubebuilder and the operator SDK utilize this library in their implementations.
The Reconciler interface provides a simple abstraction between the object detection lifecycle and the state management process. Your implementation only needs to deal with the process of managing the state of a single object, while the manager can handle the detection of target resource additions, updates, and deletes.
client-go
The controller-runtime project is by no means the only library to use for writing a controller. You can take the approach that internal Kubernetes resources use, such as the deployment controller, by using the informer mechanism in the underlying library client-go. This strategy provides more direct control and utilization of the Kubernetes client-go caching, queuing, and filtering mechanisms.
knative
There is also the approach provided by the knative tools repository, which has a similar interface for a Reconciler, but provides a different set of interfaces for managing api-server interactions. While still built on the client-go informers, the Knative package provides utilities for managing client-side cache updates and filtering events before entering the control loop. Their controller manager process unifies the registration of both controller processes and admission webhooks via a shared work queue.
Reconciliation Phases
The design of the reconciliation loop is often independent of the underlying library. One strategy that many projects use, for example in the Cluster API project and Tekton, is to structure the reconciliation process into a set of phases. These phases outline the necessary steps to manage the complete lifecycle of a resource.
For example, let’s take a 10,000 ft. view at the implementation of a Tekton Task. A Tekton Task creates a Kubernetes pod to complete the steps defined within the Task. Each step is executed within a container in the pod and the Task proceeds linearly from one step to the next. The phases of this process can be expressed fairly neatly:
- Check the Task to see if its has been completed, canceled, or timed-out (escape hatches)
- Initialize specific status fields if the Task has just started
- Create the pod that will run the Task
- Check the status of each individual step inside of the Task
- Collect the results when each step completes
Each of these phases has some dependency on the previous phase. You cannot collect results if the step has not completed, you cannot check the status of a step if the pod is not running. Each phase builds on the previous one to ensure that the full lifecycle of the Task is completed.
The key point about testing controllers which adopt this phased approach is that each one of the phases provides an independent operation that we can validate in our testing lifecycle. By providing the appropriate inputs via Kubernetes resources with specific state to the phase under test, we can validate the exact behavior that we want to achieve during that phase of the reconciliation process.
Local Testing Approaches
We want to validate our interactions with the Kubernetes API server within the context of our reconciler. Looking at examples in the open source community, we find two main dimensions for these types of tests:
- How real is the api-server we are testing against?
- How is the controller process invoked?
Let’s explore these two dimensions further and determine if there is a basic paradigm we can use to determine which approache may work best for our situation.
How real is our api-server?
The answer to this question is surprisingly not a binary, but split into three possibilities. The first possibility is that you use client-go fakes (or a higher-level abstraction of fakes) to completely avoid having to run any backing API. The Kubernetes built-in reconcilers, with their direct interactions with the informers, also take this approach, but use a real informer directly with fake data loaded into their informers.
The intermediate possibility is using the envtest package from controller-runtime. Envtest works in conjunction with a pared down version of the Kubernetes api-server to start up a server with the only reconciler being the one under test. This allows you to validate real interactions with the api-server, including timing and cache syncs, without interference from other controllers. This is excellent when your downstream resources may be picked up by other reconcilers, such as a pod that needs to be scheduled or a service searching for matching endpoints. We can test the data as it appears in the Kubernetes API rather than Go objects that haven’t traversed over the wire.
Finally, we can run a real api-server and test our interactions against that. This is great for staging environments or standing up ephemeral kind or microk8s instances to test real outcomes. For controllers that stand up real external resources requiring credentialed access, this approach can provide the best end to end validation of the expected behavior of our controller.
One of the nice things about the envtest package is that it supports both of the latter two approaches. You can provide envtest a Kubeconfig to a currently running environment and when Started it will respond with the same client-go rest.Config object. That is a major advantage of using this package in our tests; we can write validations that can be run locally against a pared down instance and then use those same tests against a fully functional cluster.
The advantage of an external process (as in both envtest and a real api-server) is that it gets rid of the immediacy that a fake client provides. Our controller is intended to operate within a distributed system, we send an event and wait for the API to tell us to process this once again. Our tests can account for this latency using a library like Gomega to wait for a specific condition to be met after an action occurs.
Reconcile Invocation
The second key differentiator in testing controllers is how the Reconcile method will be invoked. There are no surprises here, either you can test via loading your controller into a controller-manager that will use its interactions with the api-server to invoke the method for you, or you invoke the controller directly.
Testing via loading into a controller-manager can be useful to ensure that appropriate changes to state cause the correct reconciliation process to execute. This allows us to ensure that our reconciler makes a change after an action occurs by making a change that should trigger reconciliation and then ensuring the appropriate downstream effects take place (eg. creating a Deployment and watching for a ReplicaSet to be created)
This isn’t the only way. Instead, by providing the expected input data directly to the Reconciler implementation, you can fake out the Kubernetes API responses and confirm that the downstream requests to Kubernetes are structured exactly as desired. Tekton and Crossplane both take this more direct approach, in these projects, tests pass specific Kubernetes API resources to a fake client and then ensure the reconciliation process has created the desired set of requests to downstream faked APIs. For example in Crossplane’s case, tests pass faked interfaces for the cloud provider and confirm the structure of the data passed to that interface.
Real-Life Examples
Looking across the landscape of open source tools, these different approaches appear in interesting combinations. Let’s take a look at a few samples:
| Project | How Real is API | How is the Controller Invoked |
| Kubernetes deployment | Fake client | Direct invocation |
| Crossplane | Fake client | Direct invocation |
| Tekton Tasks | Fake client | Direct invocation |
| Kubebuilder | Envtest | Controller-manager triggers reconcile |
| Cluster-api | Envtest | Controller-manager triggers reconcile |
| ingress-nginx (controller) | Go structs | Direct invocation |
As we can see in these samples, using an actual api-server pairs nicely with registering our controller into a manager implementation, while fake client usage often pairs with direct invocation of the Reconcile method.
The ingress-nginx controller provides an interesting example for layering their testing approach. Their controller has a set of steps it works through based on the Kubernetes object under reconciliation, and each of those steps is unit tested directly. Then, the nginx interaction is tested by spinning up a real nginx server endpoint and validating the requests that are sent to that endpoint based on reconciling a real Ingress object. In this case, the tests need neither a fake client or a real API server, because a single Ingress object is their only interface to the Kubernetes API.
You can see that ingress-nginx also uses envtest! The project implements their own controller-manager called k8sStore and uses envtest to validate Kubernetes objects that appear in the store queue based on a specific update. Most custom controller projects should not require their own implementation of this logic.
The controller-runtime project also comes with some advice that I’d be remiss to leave out. They provide this feedback to those getting started writing controller tests.
The fake client exists, but we generally recommend using
envtest.Environmentto test against a real API server. In our experience, tests using fake clients gradually re-implement poorly-written impressions of a real API server, which leads to hard-to-maintain, complex test code.
Whether this suggestion rings true for your use case likely depends on the level of interaction your controller has with the Kubernetes API. If you rely on the manager to provide you with Kubernetes resources to reconcile, but do not interact with the API downstream outside of status updates, faking the API server is likely not an issue. On the other hand, with more complex Kubernetes API integration, it may be helpful to test against a real instance.
Our Sample
We’ve created a sample repository that will outline these concepts in simple examples that you can use as a pattern to build your own controller tests. Let’s start with a mockup of our Reconciler code.
func getRandomNumber(randomNumber RandomNumber) int {
return 4; // chosen by fair dice roll, guaranteed to be random
}
func (r *randomNumberReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
superRandomConfigMap = &v1.ConfigMap{
metav1.ObjectMeta{Name:req.Name},
Data: map[string]string{"random":getRandomNumber(client.Get(ctx,req))},
}
client.Create(ctx, superRandomConfigMap, metav1.CreateOptions{})
}
Let’s use this simple Reconciler to demonstrate each of these three test types.
Fake Client
We’ll start with a test using the fake Kubernetes client.
We set up a standard Go test to invoke Reconcile.
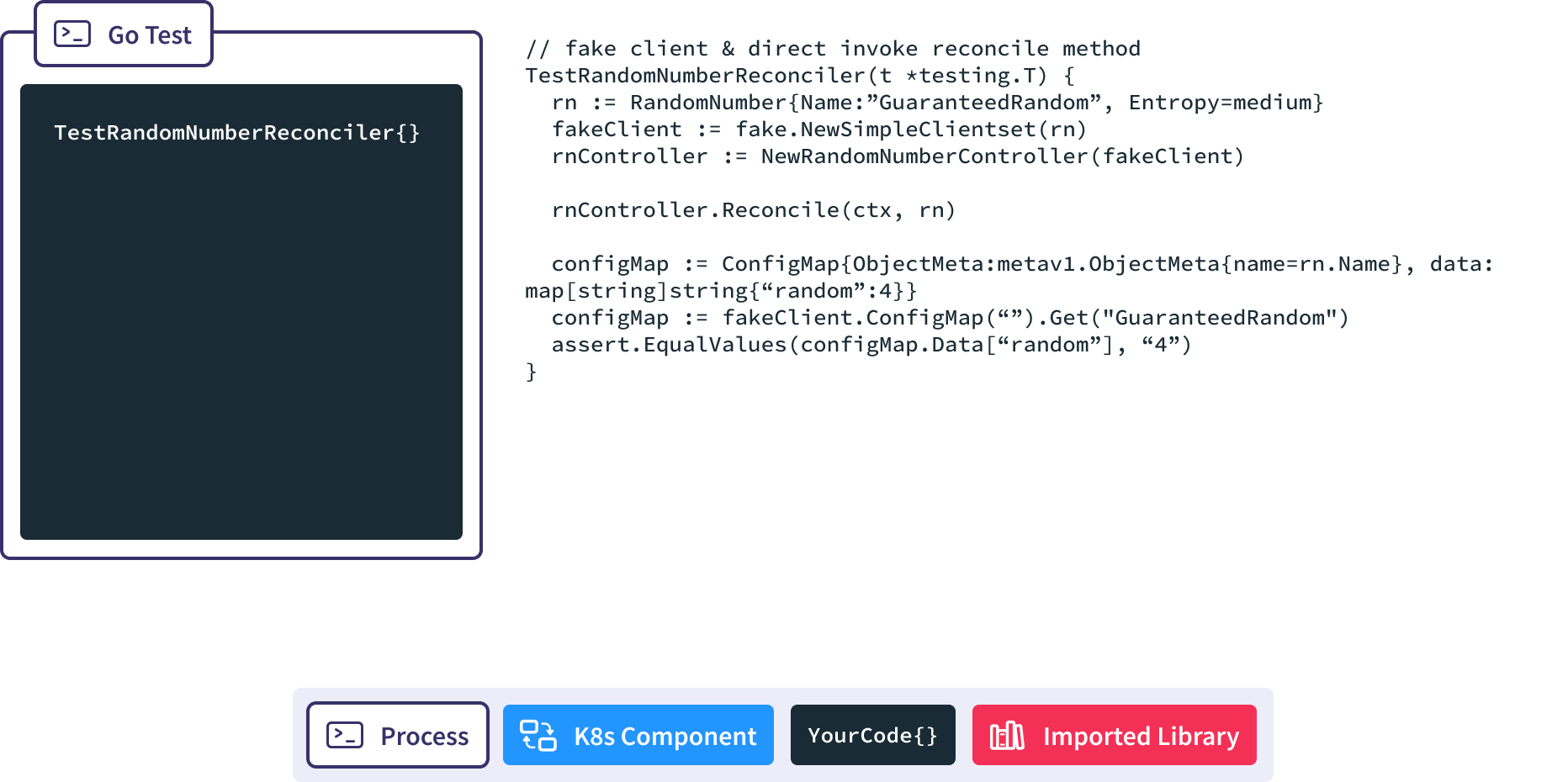
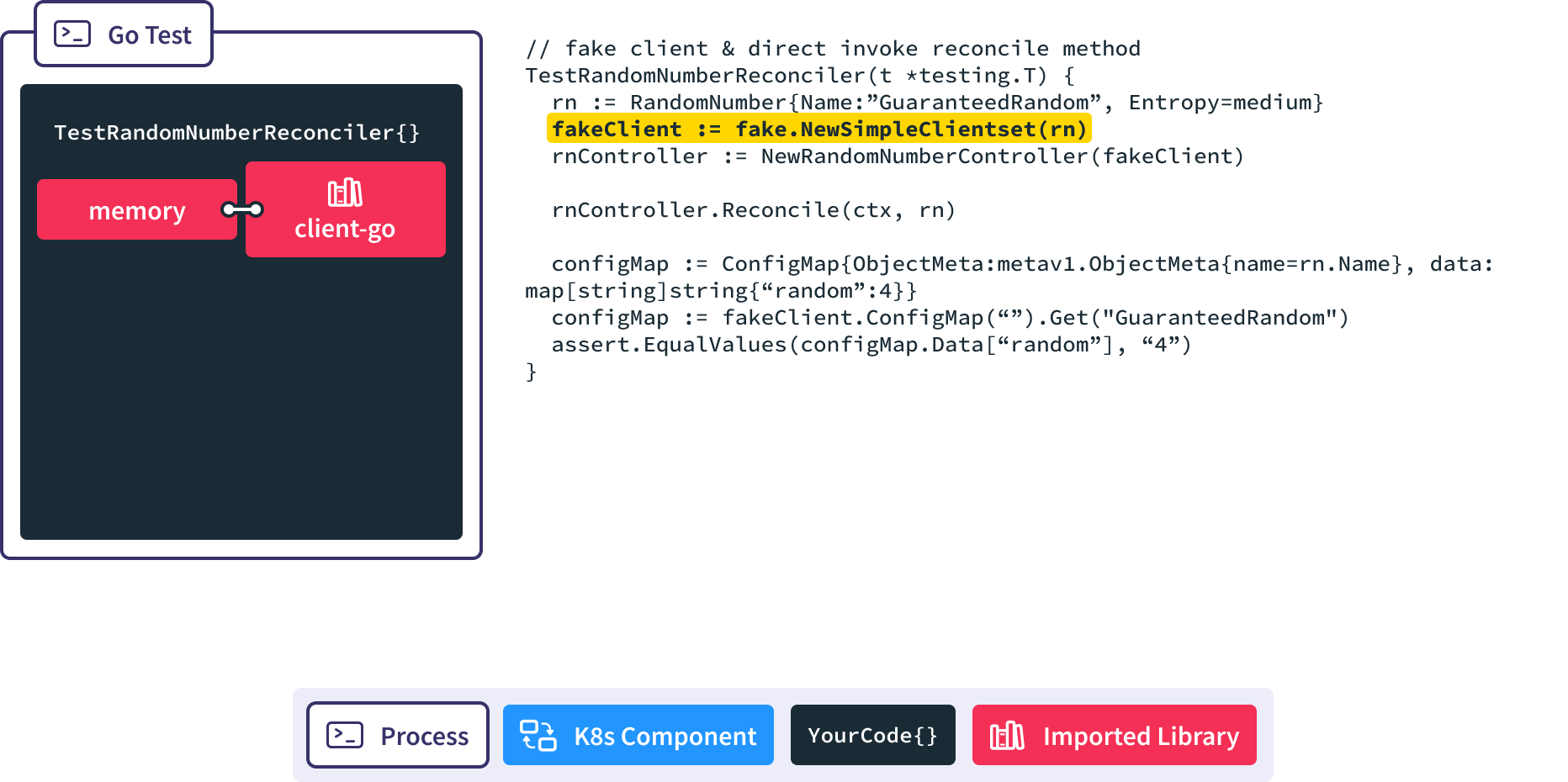
First, instantiate a fake, memory-backed instance of client-go.
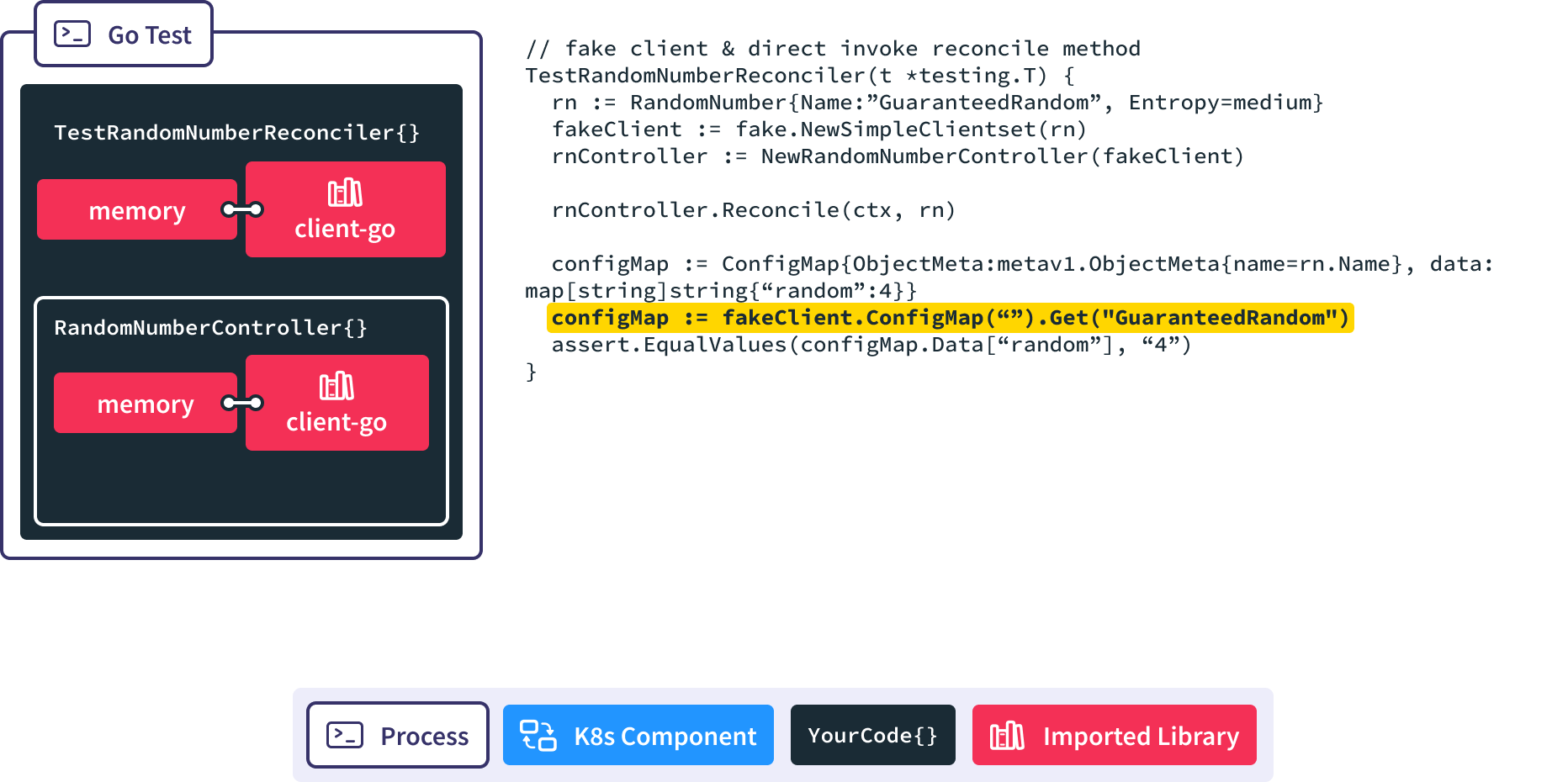
Then we spin up a new RandomNumberController and pass in a reference to the memory backed client-go.

When we call the Reconcile() method we pass in the RandomNumber resource we want it to handle.

Finally we use client-go to retrieve the resulting configmap from memory so we can make assertions against it.
Envtest Sample
Now, let’s take a look at the lifecycle of an test using the envtest API server.
Ginkgo BeforeSuite handles all the global test set up.
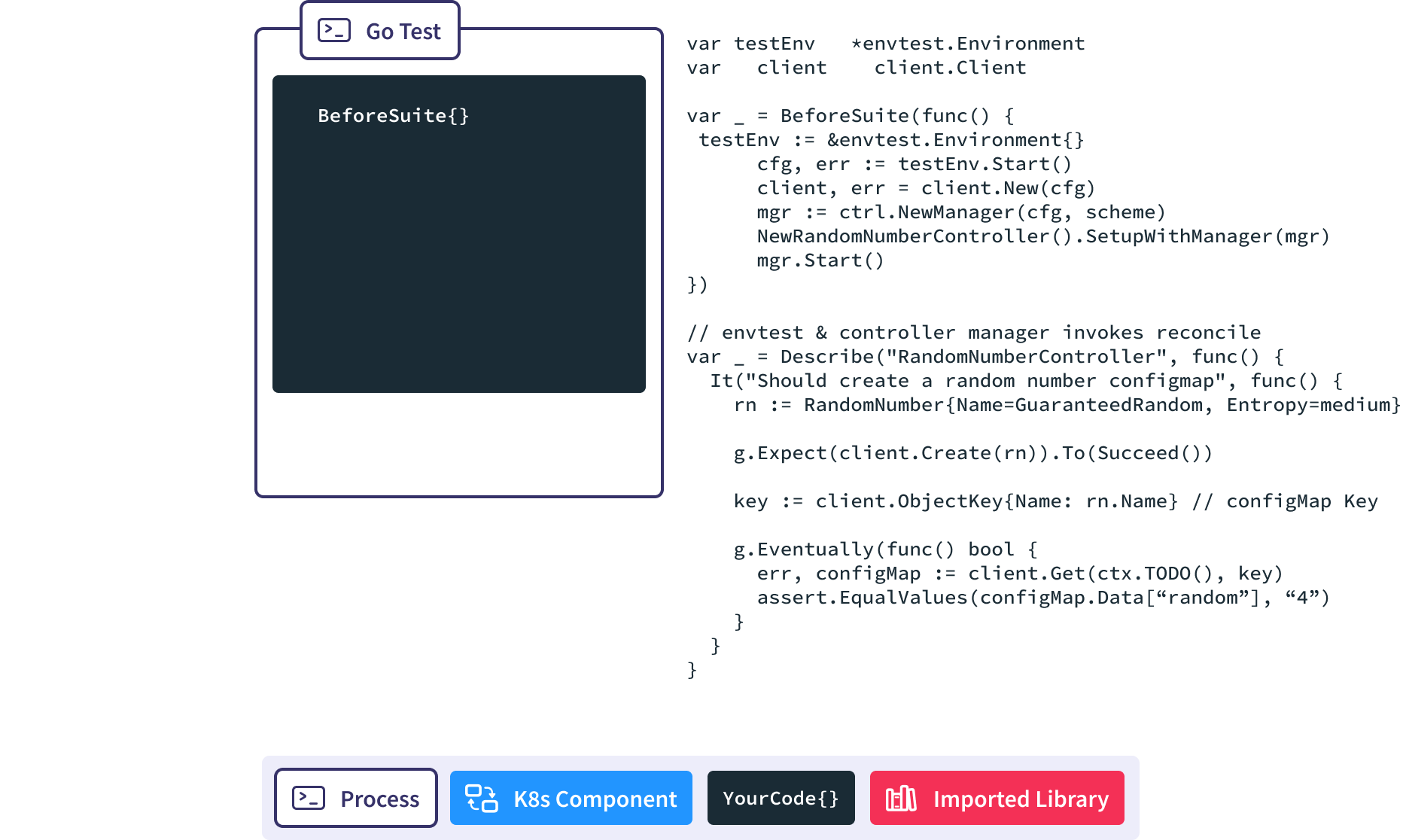
In this BeforeSuite, we use envtest to stand up a full kube-apiserver and etcd process.
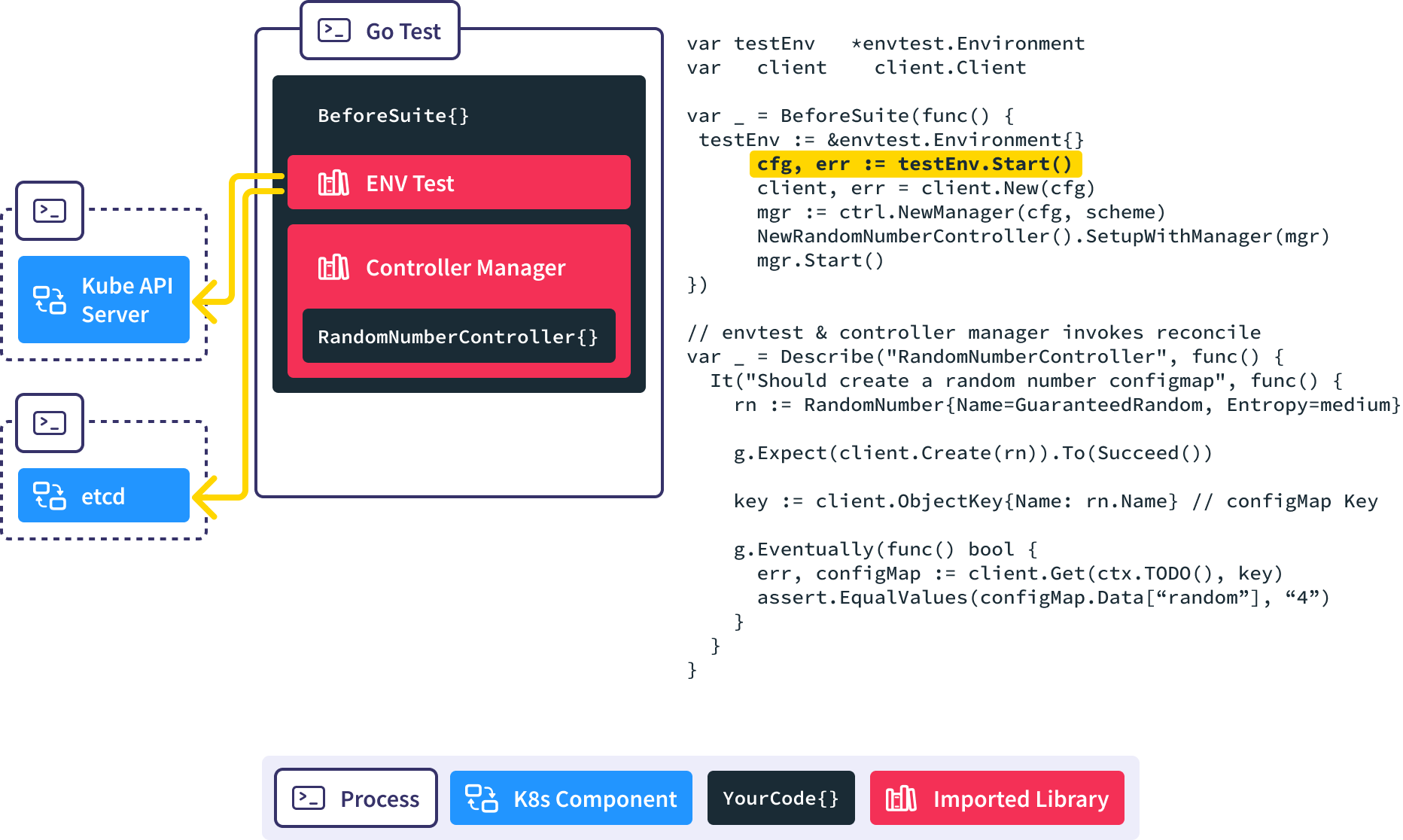
Create a new Controller Manager, inject our custom controller into it, and start the reconciliation loop. This causes the controller manager to put a watch on RandomNumber resources in the API server.
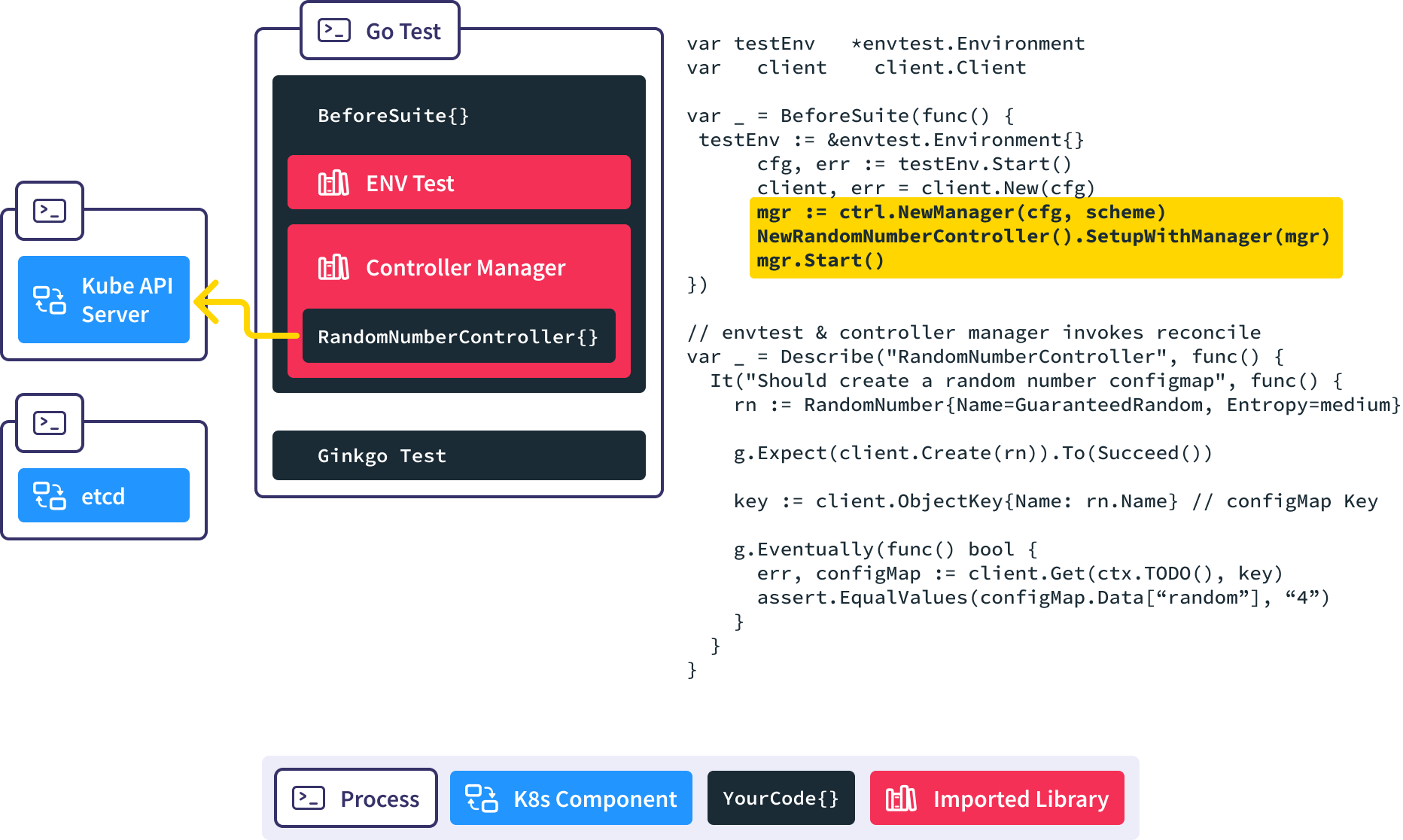
Next our test code creates a new RandomNumber resource in the API server.
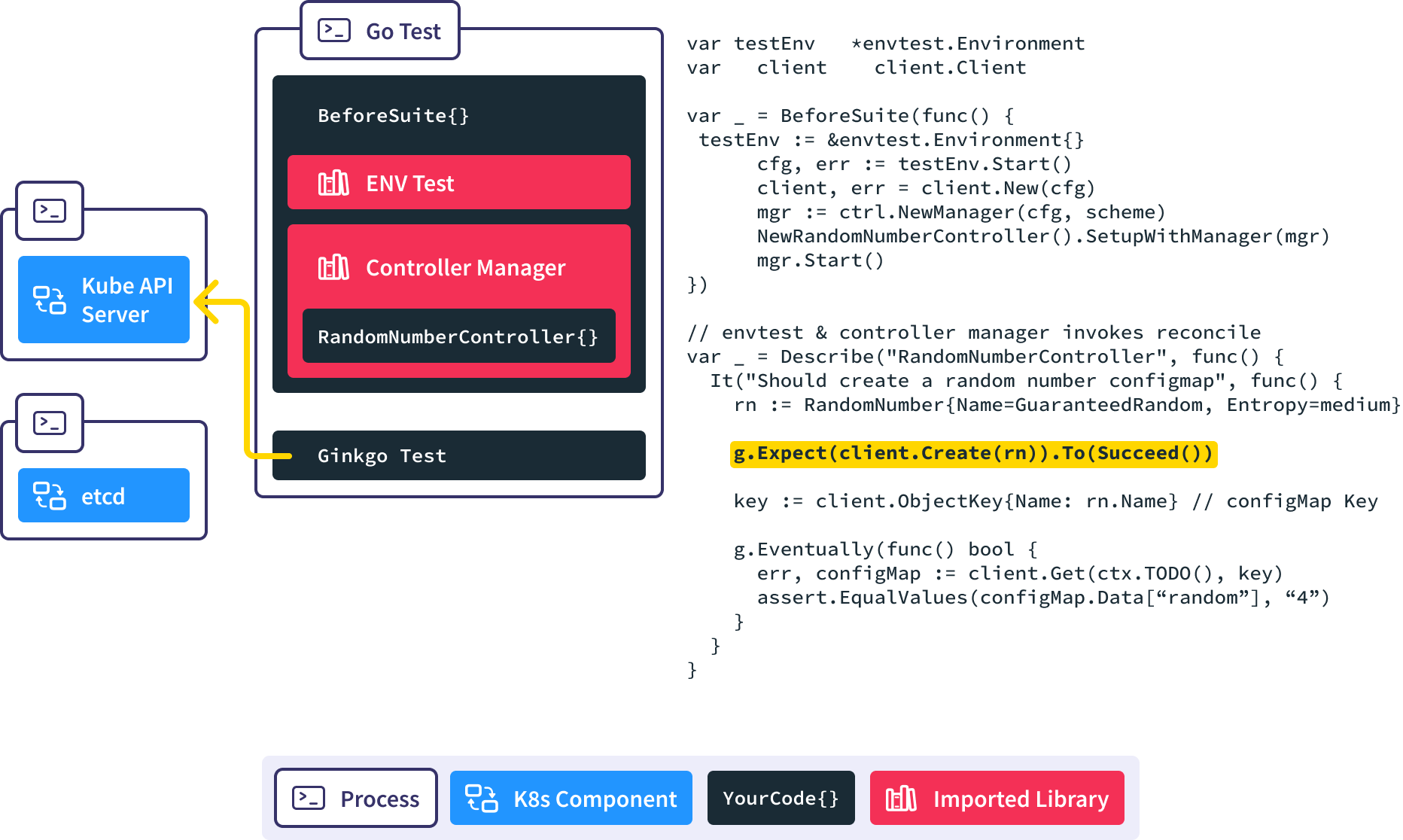
The controller manager is notified via the watch.
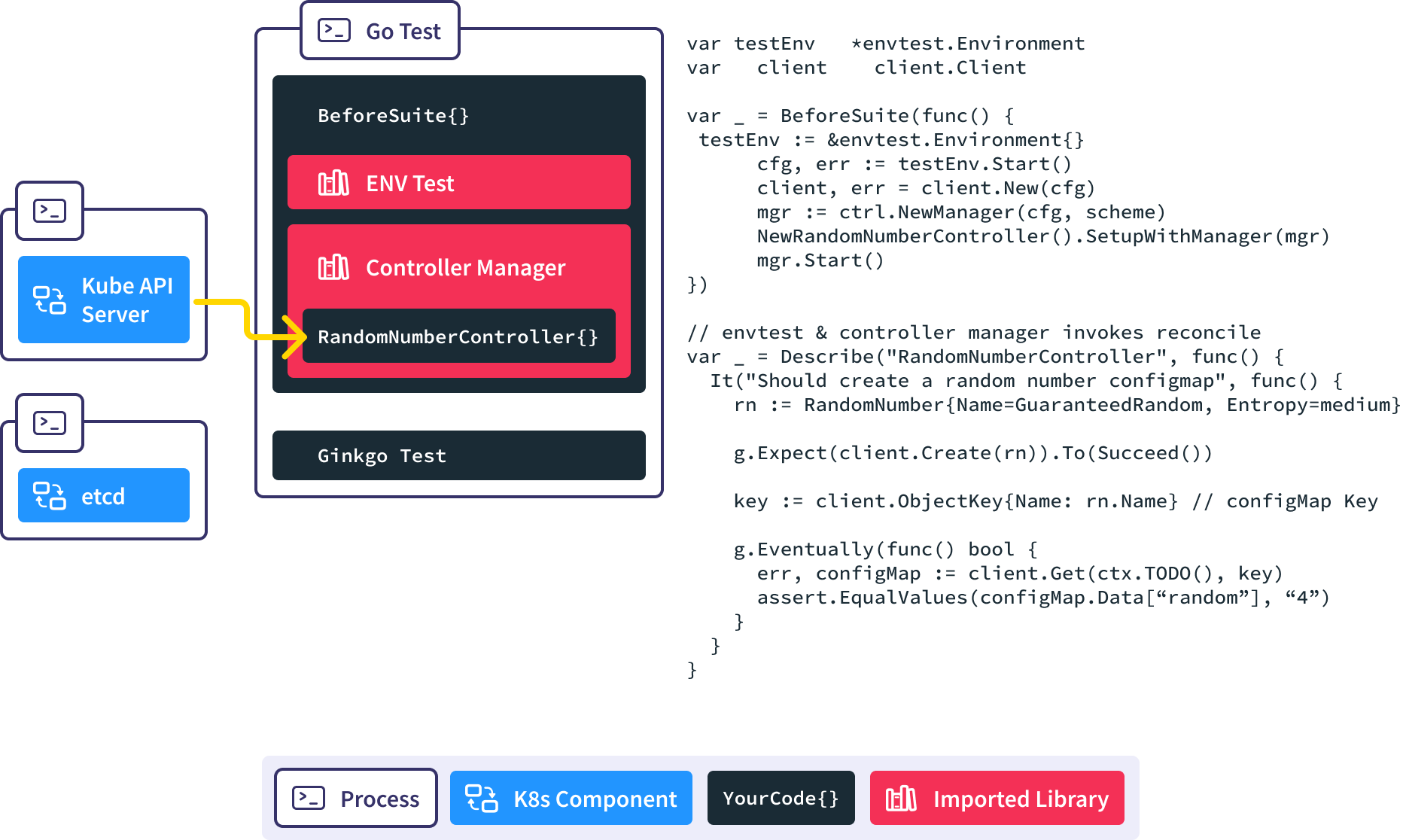
The Reconcile() method is invoked automatically in response to the new RandomNumber resource being created, and our controller creates the corresponding ConfigMap for us.
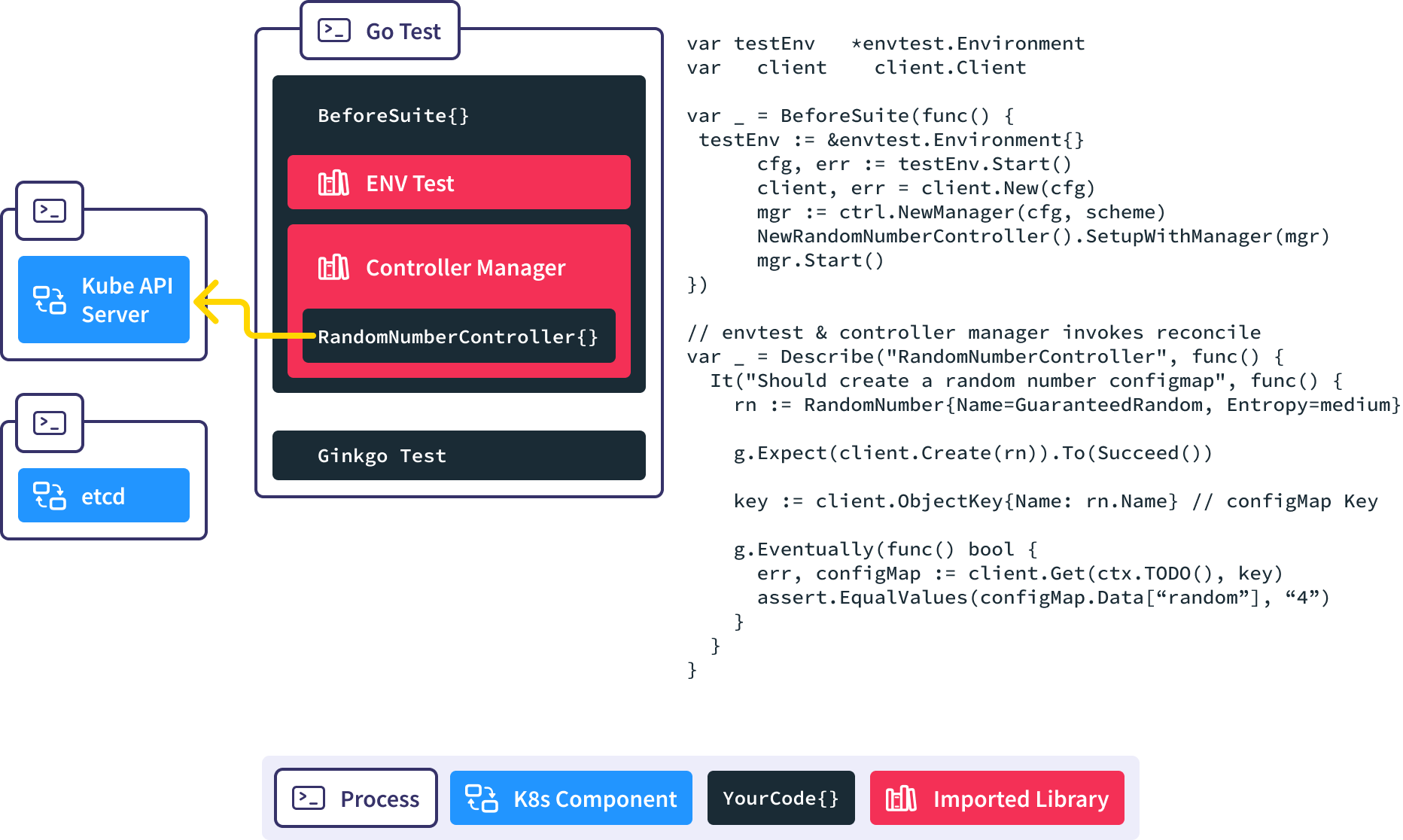
We use the Gingko async utility to query the API server until we find our expected ConfigMap or time out and fail the test.
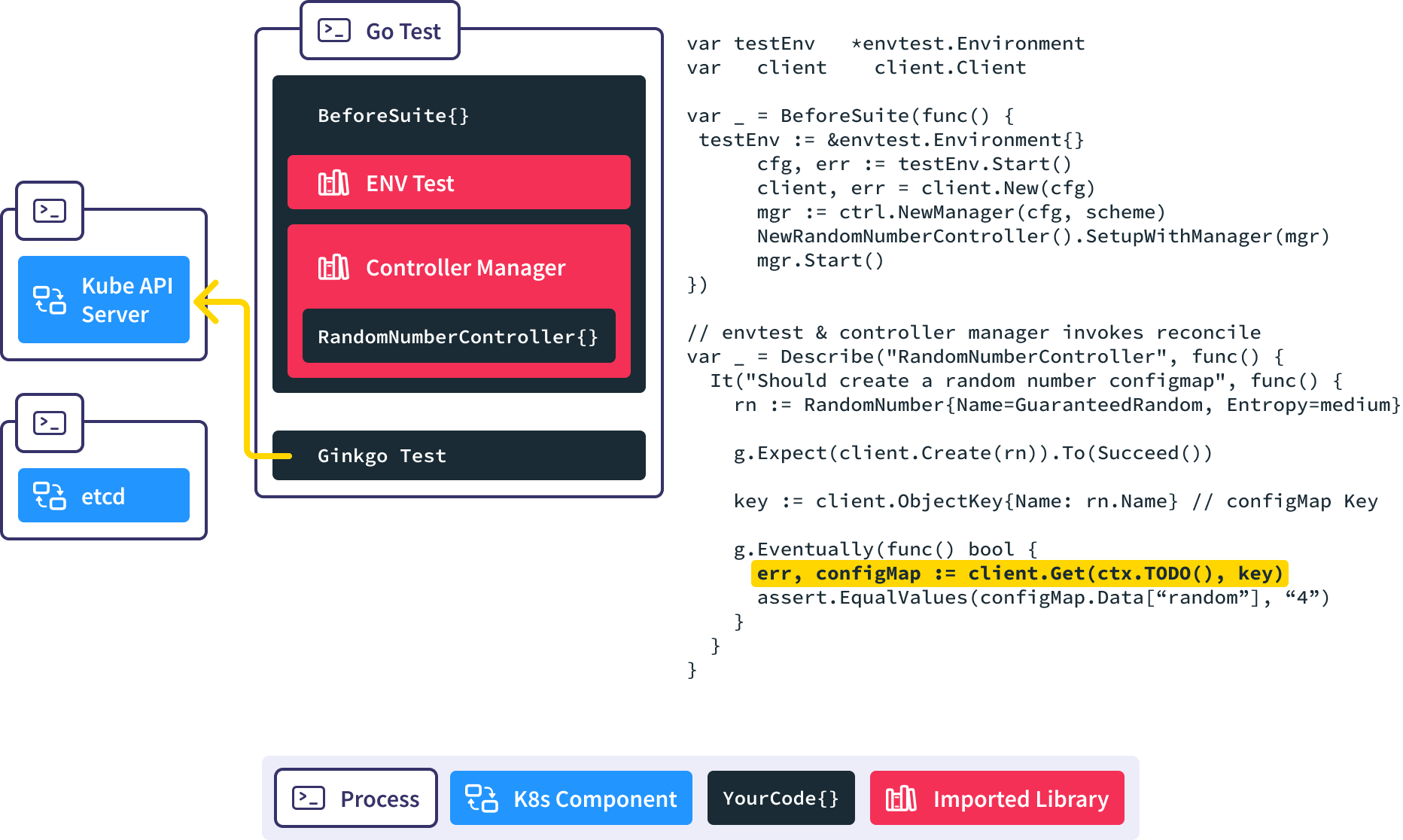
When this test completes, the AfterSuite tears down the initialized Kubernetes API Server and etcd processes to clean up the test execution environment.
End to End Testing
Martin Fowler has written an excellent article outlining a more general approach to testing. In “The Practical Test Pyramid”, he writes:
Stick to the pyramid shape to come up with a healthy, fast and maintainable test suite: Write lots of small and fast unit tests. Write some more coarse-grained tests and very few high-level tests that test your application from end to end
The first section of this article outlines a set of coarse-grained tests that we can add into the pyramid to ensure the health of our application. We discussed how to refactor your controller to expand the scope available for unit tests, as in the ingress-nginx example. This section discusses building end to end suites around this functionality.
One of the challenges about writing generically about these types of tests is that each controller implementation is context-dependent. Crossplane handles cloud resources, ingress-nginx handles configuring nginx with respect to ingress resources, cert-manager fetches certificates from a variety of sources. In the context of a custom controller, there may be external dependencies, authentication, and setup required to be able to test the full functionality.
In this case, I argue that investing in at least a single end to end run of the controller via some test mechanism is clearly worth the effort. Set up the smallest slice of prerequisites possible to initialize a resource that your controller will then handle. Maybe your prerequisite data is small, or easily faked! Figure out exactly what is required and create that initial end to end lifecycle.
There are a number of open source projects that we can draw inspiration from.
- The popular ingress-nginx controller has an entire end to end test suite along with a corresponding setup script and configuration for a kind cluster
- Crossplane has an entire repository configured with cloud authentication for regularly testing the core and provider architecture of the project.
- Tekton and Knative both have extensive e2e test plumbing that runs the e2e tests within each repository
- The operator SDK project has a Scorecard command that executes your operator against a configuration file and set of container images.
- The Kubebuilder project has a simple local e2e test script shipped with kind cluster configuration for each supported version
Take a look at the package structure and scripting built around each one of these projects. There is nothing implementation specific about any of these tests, we should be able to take any conformant cluster and validate the behavior of the cluster against that target.
Building a matrix of controller versions against a set of resources to test and the required supported versions of Kubernetes can be daunting. Using kind (as ingress-nginx does above) or microk8s to quickly initialize a cluster with the required dependencies can allow you to create a testing workflow that can be easily validated locally and then pushed into a CI workflow.
End to End Sample
Now, we’ve taken our RandomNumberController and want to end to end test it using these mechanisms. How would we implement these tests?
Generally, the process components of an end to end test, such as an existing Kubernetes cluster, are initialized before the test code is invoked.

When we run Go Test, the Gingko async utility invokes the client-go Create() method, causing a new RandomNumber resource to be created in a real K8s API server.

When the new RandomNumber resource is created the RandomNumberController controller manager which is watching for new RandomNumber resources gets notified.
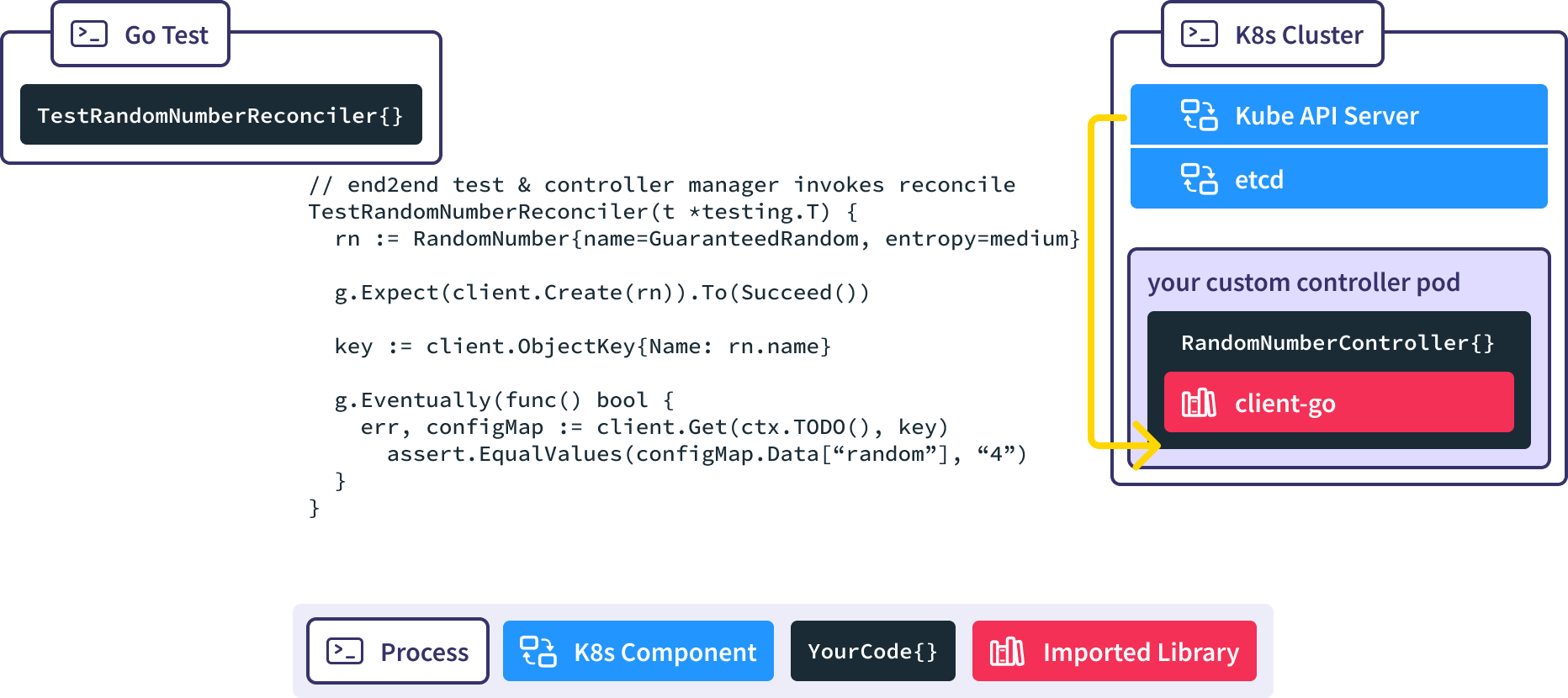
The RandomNumberController Reconcile() method is invoked automatically in response to the creation of the RandomNumber resource, causing our desired ConfigMap to be created.
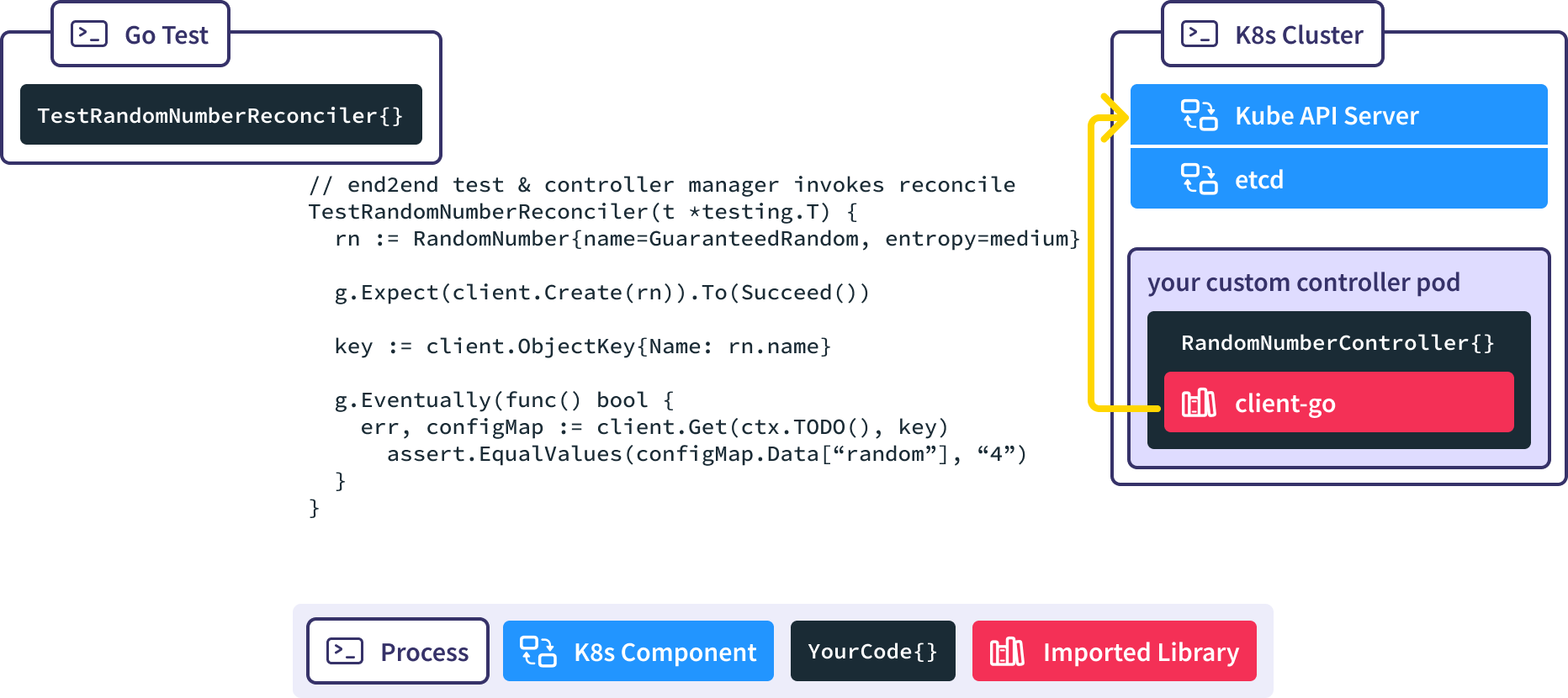
We use the Gingko async utility to query the real API server until our expected ConfigMap is created, or we time out and fail the test.
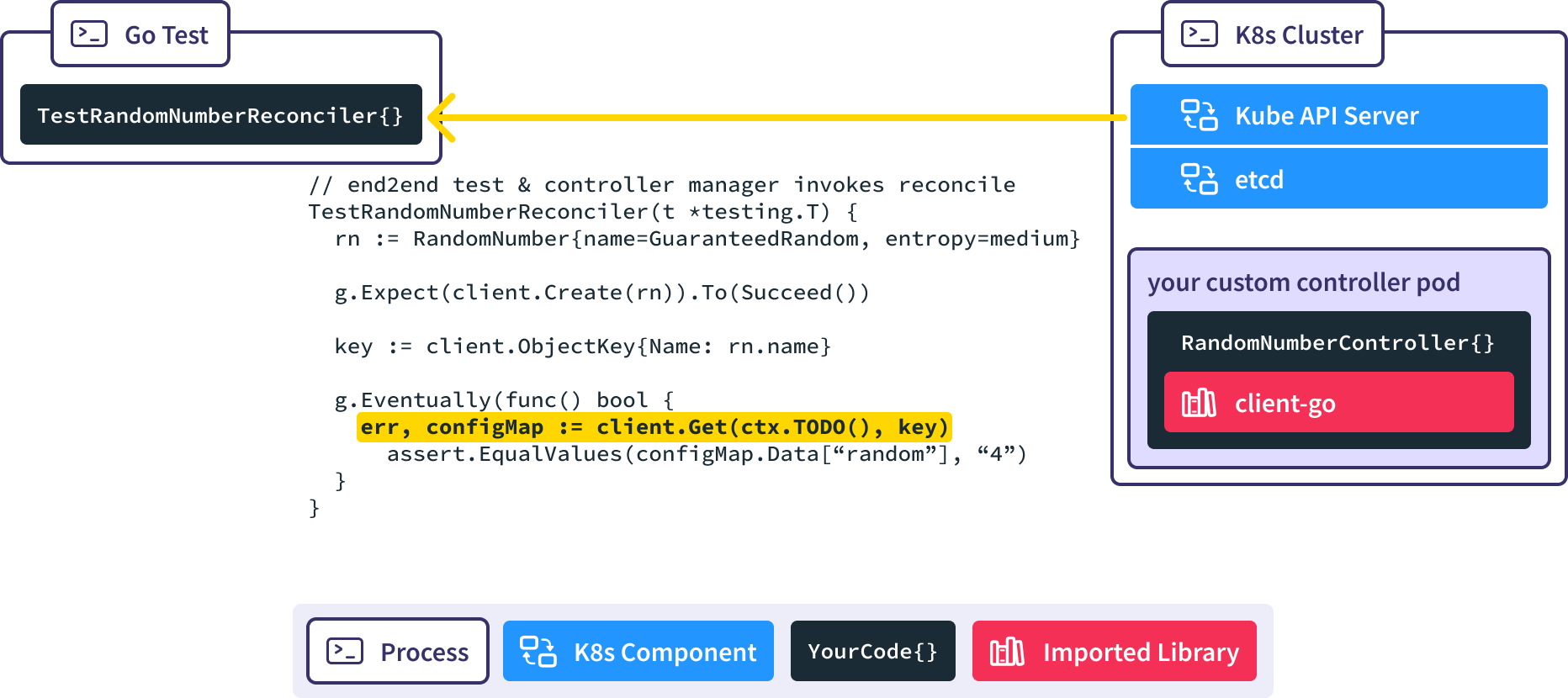
You can go check out the sample project in Github to see more about how we made it easy to run end to end tests against this controller.
Where do I start?
We’ve outlined many options here, but this can also be overwhelming. Here’s my suggestion for how to get started with controller tests.
First, build strong simple phases that operate strictly in a functional manner, taking input Kubernetes resources and returning the desired state changes or external API resources. In Kubernetes parlance, this is straightforward using the structural Go objects that are provided in the API and the generated CRDs.
Then, if you are using Kubebuilder or Operator SDK, build a small set of controller tests that use the envtest and Gingko functionality, depending on the controller manager to invoke your Reconciler. Having this baseline test in place will aid further development.
Next, invest in some basic end to end testing practices. We’ve seen examples from different projects in how they’ve tackled these things. End to end implementation requires utilizing a “real” environment with “real” credentials to the target system. The model of providing a kind.yaml paired with an end to end test script makes it extremely easy for a new contributor to run this on their own.
Finally, expand the base of your test tree to increase the scope of things that can be tested locally. If your controller relies heavily on interaction with the Kubernetes API across a set of resources, investing in tests with the natural asynchronicity of the api-server with envtest makes more sense. If your library has a more straightforward interaction with a simple external API, utilizing the fake mechanisms in your controller-runtime library may make more sense. Our goal is to create a broader set of tests that instill confidence in the underlying controller. The e2e tests are helpful to validate functionality, but broader code coverage will be accomplished by writing tests that can provide developers with a tighter feedback loop.
Go forth and test your controllers! We would love to hear more about what you are doing in this space so feel free to tweet us @superorbital_io or write to hello@superorbital.io. We also have a programming Kubernetes course that gives you a chance to get hands on with this material and would love to train your team on developing Kubernetes custom controllers today.