
Published on July 26, 2023
This is the first post in our series on running a fleet of Kubernetes clusters. See Kubernetes Fleet Capabilities: What makes a fleet? for Part 2 of this series.
Table of Contents
In the Beginning
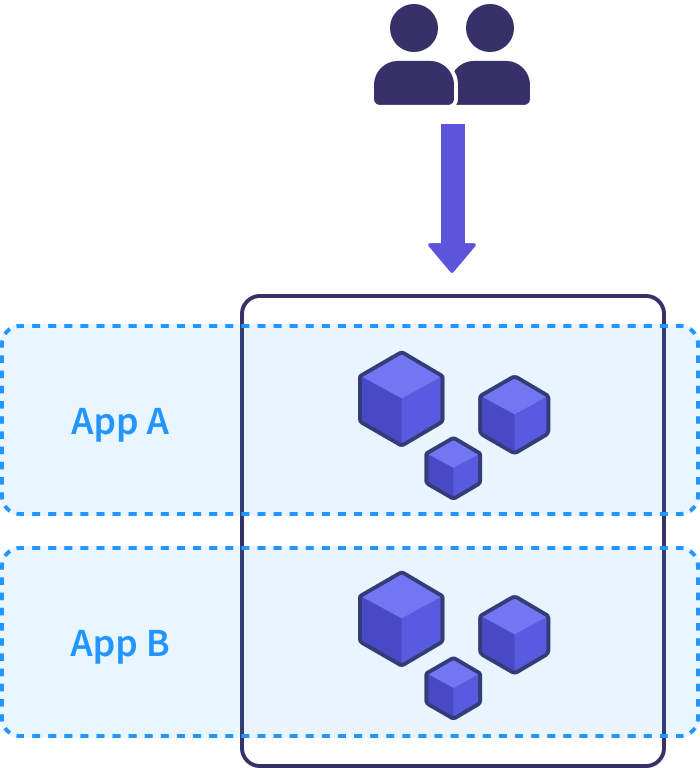
When teams first adopt Kubernetes, it’s natural to follow a clusters-as-pets pattern: the team provisions a single production cluster and deploys workloads inside it. Ingress controllers route requests to backend pods, communicating to services running in the cluster and requesting data from external backend state stores. This cluster is special - there’s only one production cluster, and it probably has a spiffy name like “Endor,” “Isengard,” or if you’re boring like me, just “prod.”
There’s nothing wrong with this approach, and it often serves a team well through moderate production usage. It’s always good to start simple and stay there for as long as practical.
But as teams grow and their usage increases in scale and complexity, they start to feel the pain of relying on a single cluster. They gain scars from in-place Kubernetes upgrades, hit scaling limits and performance bottlenecks, and scramble to restore services when issues with their pet cluster cause site-wide downtime.
We’ll take a look at some of these other concerns later on, but our story starts with the pain of upgrading a pet cluster.
The Upgrade Wars of 2018
Since its initial release, Kubernetes has been an exciting technology, and a lot of teams were very eager to adopt it early on. Of course, with early adoption comes rough edges. The lack of a smooth upgrade process was one of the worst. The public clouds hadn’t released reliable managed solutions yet, the core team had to go through a painful upgrade of etcd, and the whole upgrade process was known to be fraught with caveats and pain points. Just look at the messaging from a blog post back in 2017:
“Before you even make the decision to upgrade to Kubernetes 1.9, you must back up your etcd data. Seriously. Do it now. We’ll wait.”

The core team has put a lot of effort into addressing these issues, and the whole process started dramatically improving since 1.12. Even so, upgrades are still a major opportunity for cluster-wide failure. API deprecations, upgrades, and interface changes (such as the removal of dockershim or significant API removals) can cause headaches to CI/CD workflows and applications dependent on these APIs.
Blue/Green Pet Clusters
More sophisticated teams made use of data center and database upgrade patterns they’ve used in the past to implement blue-green upgrades for the production clusters.
In a blue/green deployment, a new version (blue) is provisioned completely separately alongside the production workload (green). Blue is put through a testing regiment to ensure it’s healthy and able to take on the production load. Then traffic is cut over from green to blue either all at once or gradually over time. This redirection of traffic requires coordination through an external load balancer. Once all of the traffic is routed to blue, the green cluster is decommissioned.

This allowed them to roll out upgrades to Kubernetes and control plane workloads at a controlled pace. If an upgrade went sideways, the new cluster could be destroyed and the upgrade could be rescheduled for after the issues were identified. Just as before, many teams got to this step and rightfully stopped. This process served them well, and there wasn’t much value in going further.
But some weaknesses remained.
Scaling Limitations
Kubernetes has been able to support larger and larger clusters with each release. However, we consistently see teams hitting scaling limitations in individual clusters much earlier than they anticipate. There are plenty of ways to outgrow a cluster - poor IP address allocation, too many virtual NICs attached to nodes, noisy neighbors, arbitrary infrastructure quotas, API server resources, metric server overloads, and even exhausting the available compute in the region. Our customers have seen them all.
The blue/green upgrade process can help you route around poor planning in the initial cluster deployment, but you’ll always be fighting an uphill battle as your cluster usage increases.
Extra Moving Parts
A blue/green upgrade necessarily introduces more moving parts and manual processes. Each upgrade requires invasive load balancer configuration changes, workload migrations, and possibly rollbacks.
Clusters should be upgraded once every four months to match the core team’s release cadence, but the extra ceremony of the blue/green process makes that unfeasible. Instead, teams lag versions and go through bursts of upgrades on a yearly cycle. These upgrade bursts often hide API deprecations, causing further issues down the line.
This combination of low automation, high ceremony, and low frequency is fertile ground for outages.
Disaster Recovery and the Blast Radius
But the biggest issue is that the current production cluster is still a pet. When (not if) that cluster burns to the ground, you’ve lost the entire basket of eggs. Your blast radius is your entire production footprint, and your disaster recovery plan involves an accelerated version of your blue/green upgrade process. For most teams, this means hours of complete production downtime.
So what’s the next stage of evolution for more sophisticated teams?
Fleets
Before we dig into fleets, I want to remind you that this is all a progression of complexity. Just as teams shouldn’t blindly adopt Kubernetes, you shouldn’t ramble along this path unless the pain points above become serious issues. There is no silver bullet, and every architectural decision comes with tradeoffs.
Many of the teams that chafed under these limitations had a moment of inspiration. They realized that their ideal state was in the midpoint of a blue/green traffic cutover. At that moment: the blue and green clusters both shared the production traffic; both were running production workloads; and both of them were expendable. They extrapolated this idea and named it a “fleet” - a set of ephemeral clusters serving homogeneous workloads.
Let’s explore how this pattern works.
In a fleet, every application is deployed across every cluster. Let’s say they’re deployed identically for now - we’ll dig into more sophisticated rollout strategies and load distributions in a later article. A North/South global load balancer (GLB) acts as the single ingress for the entire fleet and routes user requests to workloads across all healthy clusters.

This means that every cluster in the fleet is homogeneous with each other (fancy for “they’re all the same”). Because they’re homogeneous and because workloads are spread evenly across them, each cluster becomes ephemeral. In other words, we don’t sweat it if an entire cluster falls over sideways.
I like to think about this approach along the lines of the progression of database technology over the past 25 years. Initially, we had single-node databases, followed very quickly by databases supporting read-only replicas with asynchronous replication. Then, some databases supported local multi-write capabilities. Finally, Google released their revolutionary Spanner paper, documenting a scalable, multi-version, globally distributed, and synchronously-replicated database.
Scalability
This approach provides extreme scalability. You can easily add or remove clusters, scaling your fleet horizontally to match demand while avoiding all of the bottlenecks of a single cluster. Your fleet can easily grow from three to thirty clusters without much extra overhead.
Fleet Upgrades
The fleet upgrade process is an extrapolation of the blue/green upgrade process that completely changes the operating model. Let’s start with a healthy state for our applications and users.

When it’s time to upgrade the clusters in a fleet, a new cluster is provisioned with the new version. The workloads are provisioned into it just like the rest of the clusters. A health-check suite is run against this cluster, and then it’s added to the fleet by registering it with the GLB.

This allows a small percentage of traffic (25% in our example) to be routed to the new cluster. We can even control that amount and the pace of the rollout by ramping that traffic up over time. We observe the workloads on the new cluster, ensuring they’re operating within the same parameters as the other clusters. If we ever see any anomalies, we can pause the rollout and take our time investigating, or just trash the new cluster and start again later.
While we’re in this state, we’re pretty significantly overprovisioned. We’re running four clusters when three are more than enough to serve our needs. Once we’re satisfied with the health of the new cluster, we deprovision a random old one and get ourselves back to the proper size.

Then it’s a matter of repeating the steps until all of the clusters are upgraded. This has become a highly-automatable process that can happily run over the course of a week.
This does require an investment in comprehensive automated validation, but that pays off in many ways. When done right, these validations can be run continually to ensure cluster health and stability as well as to detect configuration drift.
DR? Who needs DR?
This is where things get really exciting. We can achieve DR nirvana if we run a steady-state fleet in an over-provisioned capacity. For example, in a fleet of three clusters, each should be 60% utilized (CPU, iops, etc).

That 40% unused capacity is helpful for handling traffic bursts and giving us lead time when increased demand calls for a new cluster to be added to the fleet. But most importantly, that overhead allows the healthy clusters to absorb the traffic when a disaster event takes out one of their neighbors.

This means we can survive the loss of an entire cluster with nonchalance, replacing it at our leisure, knowing that the rest of the clusters have shouldered the load. If we’ve fully automated the cluster upgrade process, we may not even have to take action for a new cluster to be provisioned and put into rotation.
We can optimize this further by spreading the fleet out across availability zones and regions, but we’ll dig into that meaty topic in another article. As a teaser: This can actually save you money.
Stay tuned
In this article, we’ve covered the what and the why of fleets. In future articles, we’ll get deeper into the how, look at some tools designed to manage fleets, discuss some more sophisticated options, and come clean about when fleets won’t help you. Subscribe (yes, we still ❤️ RSS) or join our mailing list below for future articles.
If you’d like to learn more about how to implement this pattern within your own organization, we’d love to talk. Schedule a free 30min consultation, or email us at hello@superorbital.io.