
Published on May 30, 2024
Table of Contents
Server-side apply is a critical mechanism to understand when building custom Kubernetes controllers, but the Go type system can be convoluted and difficult to tease apart. Here’s how we walked our students through it during a recent workshop.
Overview
During the last run of our Programming Kubernetes course, a student asked about the Go type system embedded within the server side apply mechanism of client-go. When learning about Kubernetes, it is always helpful to go back to the source of the conversation which exists in the form of a KEP.
KEP-2155 outlines the motivation, proposal, and design decisions behind server side apply and outline the history of the development of this capability within the Kubernetes source tree.
When reading KEPs, the final state of the document never tells the whole story, let’s take a look at the file’s history:
In the second version of the KEP on Github,
the contributors suggest that many alternatives have been proposed to represent an Apply resource. These alternatives remain in the current version of the document:
- Generated structs using pointers for all field representations
- Use a YAML document
- Combine the
client-gostructs with a mask - Use variadic function-based builders via generated types
Let’s talk about how this decision was made and how to work with the generated builder types in our code.
Choosing a Direction
One of the key aspects of the server-side apply mechanism is that declares ownership over the set of fields specified in the request. Because
the Go representations of many baseline Kubernetes resources have zero-valued
elements. Because of this, baseline client-go types cannot be used to represent a server-side apply operation, as there would not be a way
to differentiate between a request containing a zero-valued element and a request where an un-set element has been set to the zero value.
This leads to two of the alternatives outlined above, the field mask and the pointer representation option. The field mask is inherently error prone, as a duplicate representation of the same data structure with two different meanings. There’s also the challenge of interpreting the results of that operation, as there is no tie between a field set in the base client resource and an update to the mask.
Constructing analogous pointer types was one of the two mechanisms hotly debated as the implemented solution here. While feedback between that and variadic builders was mixed, it appears that the difference in shape between the baseline client-go resources and the Apply resources became a positive element of the builder approach.
A direct YAML representation approach was dismissed as not taking advantage of the type safety inherent in the Go language.
Let’s explore the implementation of the builder types and how it compares to a standard client-go resource. Before we do this, let’s understand the motivation behind server-side apply as a mechanism.
Server-Side Apply Machinery
When considering server-side use cases vs client-side, it is important to differentiate the standard use cases. While both options can be utilized in almost any circumstance, server-side is an ideal solution for a particular set of use cases.
KEP 555 outlines the motivation behind server-side apply for the API server. Key workflows involve multiple actors in a system interacting with the same Kubernetes resource. This is especially critical for resources like sets, lists, and maps, where the addition of keys by multiple actors is likely to cause a conflict if the full resource spec is submitted by two distinct actors.
It is important to differentiate this machinery from the modifying webhook mechanism, which is processed after the resource is submitted to the API server. A common confusion is that resource updates such as Istio proxy init containers and sidecars are processed by a server-side apply, but these operations are handled using JSONPatch semantics.
For server-side apply, think about operations where live resources need to be modified after creation, the canonical example being an HPA modifying the replica count of a deployment as pod utilization metrics change in the live system. Another great example is maintaining the Istio revision label on a namespace or workload resource alongside Istio control plane upgrades.
The controllers inside the main kube-controller-manager have also been updated to utilize server-side apply for status updates to a
resource. This is a natural use case for this type of operation as the status subresource is a field that can only be set after a resource is
live within the API server.
When the API server receives a server-side apply request, it uses the managedFields metadata field to specify ownership of
the structure of the resource. Let’s build a sample ApplyConfiguration and look at the resulting managedFields on the resource.
Building an Apply Configuration
Now, let’s look at how the generated builders work to modify resources and their impact on a resource spec. These API calls are a
part of the typed client packages, as the dynamic interface
can already send generic requests to the API server. Inside of each typed client, such as a DeploymentInterface,
three new methods have been added to the base functionality:
type DeploymentInterface interface {
Apply(ctx context.Context, deployment *appsv1.DeploymentApplyConfiguration, opts metav1.ApplyOptions) (result *v1.Deployment, err error)
ApplyStatus(ctx context.Context, deployment *appsv1.DeploymentApplyConfiguration, opts metav1.ApplyOptions) (result *v1.Deployment, err error)
ApplyScale(ctx context.Context, deploymentName string, scale *applyconfigurationsautoscalingv1.ScaleApplyConfiguration, opts metav1.ApplyOptions) (*autoscalingv1.Scale, error)
}
The Apply operation works on the base resource, and the two additional methods represent the two subresources
on the Deployment type.
Let’s look at the methods on DeploymentApplyConfiguration:
// source https://pkg.go.dev/k8s.io/client-go@v0.30.2/applyconfigurations/apps/v1#DeploymentApplyConfiguration
type DeploymentApplyConfiguration
func Deployment(name, namespace string) *DeploymentApplyConfiguration
func ExtractDeployment(deployment *apiappsv1.Deployment, fieldManager string) (*DeploymentApplyConfiguration, error)
func ExtractDeploymentStatus(deployment *apiappsv1.Deployment, fieldManager string) (*DeploymentApplyConfiguration, error)
func (b *DeploymentApplyConfiguration) WithAPIVersion(value string) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithAnnotations(entries map[string]string) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithCreationTimestamp(value metav1.Time) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithDeletionGracePeriodSeconds(value int64) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithDeletionTimestamp(value metav1.Time) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithFinalizers(values ...string) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithGenerateName(value string) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithGeneration(value int64) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithKind(value string) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithLabels(entries map[string]string) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithName(value string) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithNamespace(value string) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithOwnerReferences(values ...*v1.OwnerReferenceApplyConfiguration) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithResourceVersion(value string) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithSpec(value *DeploymentSpecApplyConfiguration) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithStatus(value *DeploymentStatusApplyConfiguration) *DeploymentApplyConfiguration
func (b *DeploymentApplyConfiguration) WithUID(value types.UID) *DeploymentApplyConfiguration

What is going on here?
The generated ApplyConfiguration types utilize the base Go type structure for the resource to create methods on
each level of a type. Let’s look at the baseline definition of a Deployment type:
type Deployment struct {
metav1.TypeMeta
metav1.ObjectMeta
Spec DeploymentSpec
Status DeploymentStatus
}
Where do all those methods come from then? This resource looks pretty simple?
In the DeploymentApplyConfiguration, the embedded types
are expanded into individual methods, giving us all the fields from TypeMeta and ObjectMeta
as methods on the base resource as well.
Fortunately, for most use cases, we don’t need to worry about the full available API surface as these operations are intended to be surgical within the spec. Here’s how simple a real-life example can be:
import (
applyappsv1 "k8s.io/client-go/applyconfigurations/apps/v1"
)
...
deployApply := applyappsv1.Deployment(name, namespace).
WithSpec(applyappsv1.DeploymentSpec().
WithReplicas(replicaCount),
)
deployInterface.Apply(ctx, deployApply, metav1.ApplyOptions{
FieldManager: "my-field-manager",
})
I have structured this Go code very specifically to align visually with the YAML document you would submit for this operation:
apiVersion: apps/v1
kind: Deployment
metadata:
name: "name"
namespace: "namespace"
spec:
replicas: replicaCount
The pre-amble of type information and metadata are consumed in the first line, the constructor for a
deployv1.Deployment sets the type meta and the associated name/namespace key for the resource. No apply
operation can be carried out without this five-tuple of information:
- API Group
- API Version
- Kind
- Namespace (if namespace-scoped)
- Name
Now, each level of nesting in our field becomes a builder method we fill in with a variadic argument and associated builder functions for that level of nesting.
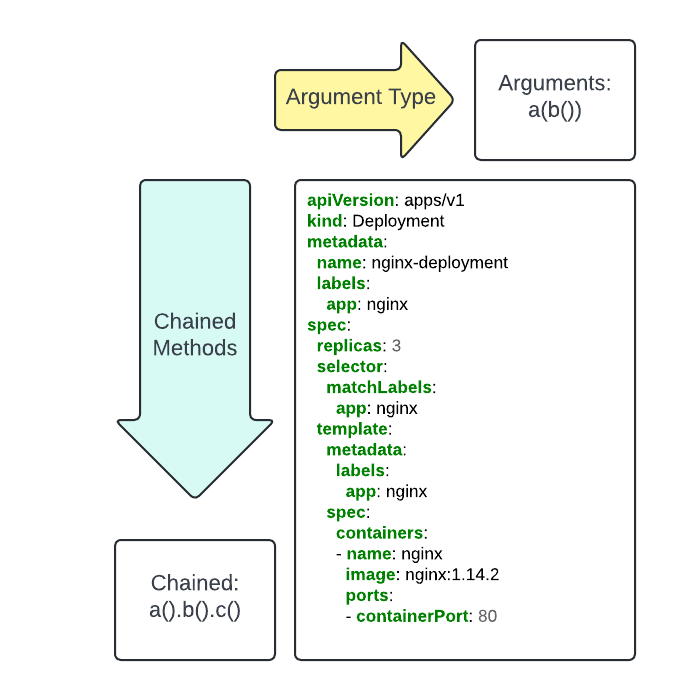
Adding Complexity
Server-side apply can be utilized to take ownership over specific values within lists and maps. This must
be done with care, understanding the OpenAPI schema extension value
associated with that type. A great example of this is the status.conditions field on a resource. As multiple controllers
may make an update to different conditions, we have to ensure that our condition listMapKey does not intersect with
another controller. Once a specific field manager sets this key, it becomes the owner of that condition:
import (
applyappsv1 "k8s.io/client-go/applyconfigurations/apps/v1"
appsv1 "k8s.io/api/apps/v1"
)
...
deployApply := applyappsv1.Deployment(name, "default").WithStatus(
applyappsv1.DeploymentStatus().
WithConditions(applyappsv1.DeploymentCondition().
WithType(appsv1.DeploymentReplicaFailure).
WithMessage("Custom controller detected replica failure for deployment").
WithReason("SchedulerFailPodSpec"),
),
)
deployInterface.Apply(ctx, deployApply, metav1.ApplyOptions{
FieldManager: "my-field-manager",
})
This creates the apply request document:
apiVersion: apps/v1
kind: Deployment
metadata:
name: "name"
namespace: "namespace"
status:
conditions:
- type: ReplicaFailure
reason: SchedulerFailPodSpec
message: Custom controller detected replica failure for deployment
The conditions map is then compared using the list-map key of type for ownership of the field.
If no other controller has the following structure in managedFields then the apply will be
processed:
f:status:
f:availableReplicas: {}
f:conditions:
k:{"type":"ReplicaFailure"}:
manager: my-field-manager
operation: Update
subresource: status
Note: see that the
managervalue in the resultingmanagedFieldsvalue matches the value ofFieldManagerwithin theApplyfunction call.
We can see the conditions of a standard “healthy” deployment as the two conditions that will be populated by
the deployment controller are "Progressing" and "Available". Note that the manager field matches
the kube-controller-manager which runs the deployment reconciliation function.
- apiVersion: apps/v1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
f:deployment.kubernetes.io/revision: {}
f:status:
f:availableReplicas: {}
f:conditions:
.: {}
k:{"type":"Available"}:
.: {}
...
k:{"type":"Progressing"}:
.: {}
...
f:observedGeneration: {}
f:readyReplicas: {}
f:replicas: {}
f:updatedReplicas: {}
manager: kube-controller-manager
operation: Update
subresource: status
time: "2024-06-14T13:09:01Z"
While this example may be a bit contrived, since the deployment controller picks up the ReplicaFailure condition and resolves it,
this gives a decent demonstration of how to own a single field within a granular list map type. In this case, we updated
the status.conditions array using the list map key of type with value ReplicaFailure. Server side is particularly adept to these situations as
it will appropriately merge the existing list with the request and
preserve the ownership with respect to the key property of the updated list.
Conclusion
Server-side apply is a critical mechanism to understand if you are building controllers that have an impact on existing Kubernetes resources. If you want to learn about this mechanism in a hands on fashion, as well as many other programming Kubernetes concepts, reach out to us today to discuss holding a Programming Kubernetes workshop for your team.