
Published on September 15, 2023
This is part of our series on running a fleet of Kubernetes clusters. See Kubernetes Cluster Fleets: From Pet to Cattle for an introduction.
Table of Contents
Overview
In the Cloud Native landscape, the fleet has been an emerging concept that remains somewhat nebulous. What constitutes a fleet? Do I need to explore constructing a fleet for my cloud deployment? Let’s dig in and explore some of the capabilities we can take advantage of.
Nowadays, it’s not surprising to hear from teams running hundreds or even thousands of clusters across all environments! A well-known example is Chick-fil-A running almost 2,500+ clusters on devices shipped to each one of their restaurants. While sig-scalability has pushed the limits of how big a single cluster can be, teams operating Kubernetes often find it easier to reduce blast radius and isolate operational concerns by working with a bunch of smaller clusters rather than one huge one. Kubernetes serves needs that exist somewhere within the massive gap between a single node and us-east-1.
As teams mature from a single cluster to multiple clusters, higher-order considerations become a factor. This is where fleet management can become an effective strategy for handling your compute needs.
Before we dive in further, I want to highlight that this isn’t just about happy-path stateless app management. Workloads that are well suited to Kubernetes like CI/CD, machine learning training, and large scale job scheduling can all effectively take advantage of these same concepts.
Fleet Level Considerations
Let’s consider the needs that emerge when operating something like a “cluster of clusters,” and we will begin to see the outline of the sort of thinking that changes a bunch of disparate clusters into a coordinated fleet.

Cluster Provisioning
At the multi-cluster scale, you run into challenges that come with the standard cluster CRUD operations. What does it take to provision a new cluster within your ecosystem? How do you safely upgrade one? Can you deprovision one that has gotten into a failed state?
Application Delivery
While there are many tools to handle the distribution of applications to a single cluster, once you have to operate across multiple control planes, you need a place to aggregate and maintain the state of those disparately deployed applications. Aggregating this status implies centralizing observability data to pinpoint global issues within a complex web of cloud APIs.
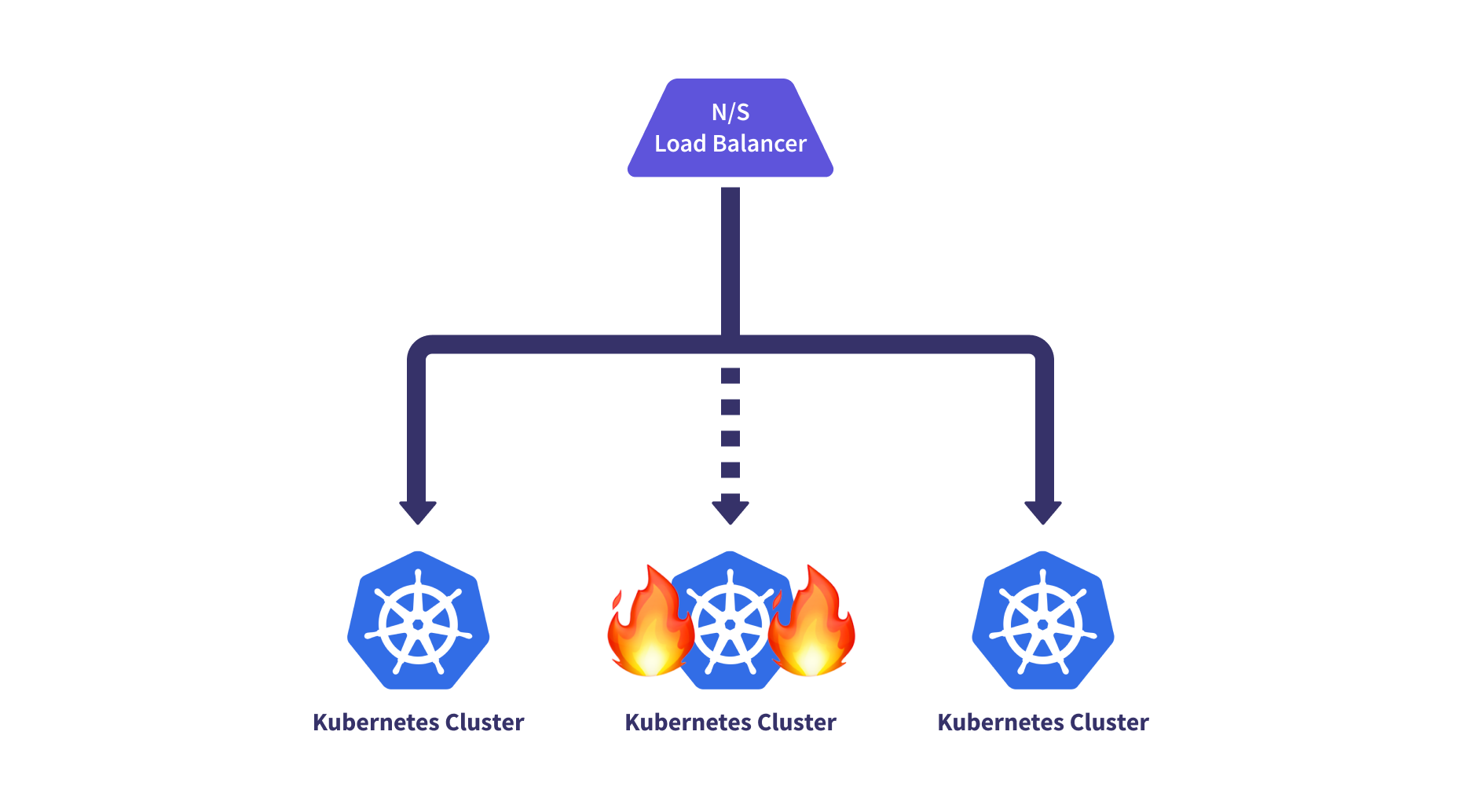
Traffic Management
Finally, multi-cluster N-S or E-W cluster-to-cluster routing can be done more intelligently when multi-cluster application awareness routes both inbound and internal service-to-service traffic to healthy clusters.
One consideration that can be important when it comes to N-S routing capabilities is ensuring data residency for regulatory frameworks, such as GPDR. This can force certain traffic to stay within a set of regions, so your routing capabilities may need to be aware of these restrictions.
So, what is a fleet?
Let’s talk about some of the attributes that make up a fleet. We again consider this along the dimensions of cluster provisioning, application delivery, and traffic management.
Cluster Provisioning
To manage the lifecycle of clusters, many products in this ecosystem provide a central way to manage the individual members, in this case the Kubernetes cluster becomes a “resource”. The desire for a new cluster could be expressed as a row in a database or as a set of HCL files in a git repo. The right solution for you depends on your scale. We’ve found that Terraform works wonderfully for a smaller fleet. Beyond that, we recommend using CRDs and Kubernetes controllers to provision clusters, managing them the way we manage applications.
This resource becomes a means of implementing CRUD operations on the cluster and an endpoint to monitor the health of clusters in the fleet. You need to be able to determine via automation the provisioned status of a cluster, the synchronization state of all applications, and the overall health of the cluster. This endpoint can then be used for further operation, such as automatic routing updates and detection of out-of-date clusters that should be replaced.
The final step in this lifecycle is cluster deletion! This operation can come with higher risks than creation, so we must ensure applications are appropriately synced and routed to other locations before the cluster is removed from rotation and deconstructed.
Application Delivery
Once the cluster is centrally managed as a resource, you want to utilize that capability to improve the overall application lifecycle. This can extend from baseline configuration, security policy, and observability tooling to globally managed application configuration.
From a policy perspective, you may want to maintain a consistent set of Kyverno policies across all clusters or ensure all Prometheus instances are rolling up into a central metrics store.

Once applications are delivered to clusters from a central control point, you want information about the resulting resources to feed back into that single pane of glass. You should be able to visualize per-cluster application status and performance information across clusters. This could be as simple as aggregating metrics and events across multiple clusters, combining them into a single view, grouped by their global workload identifier.
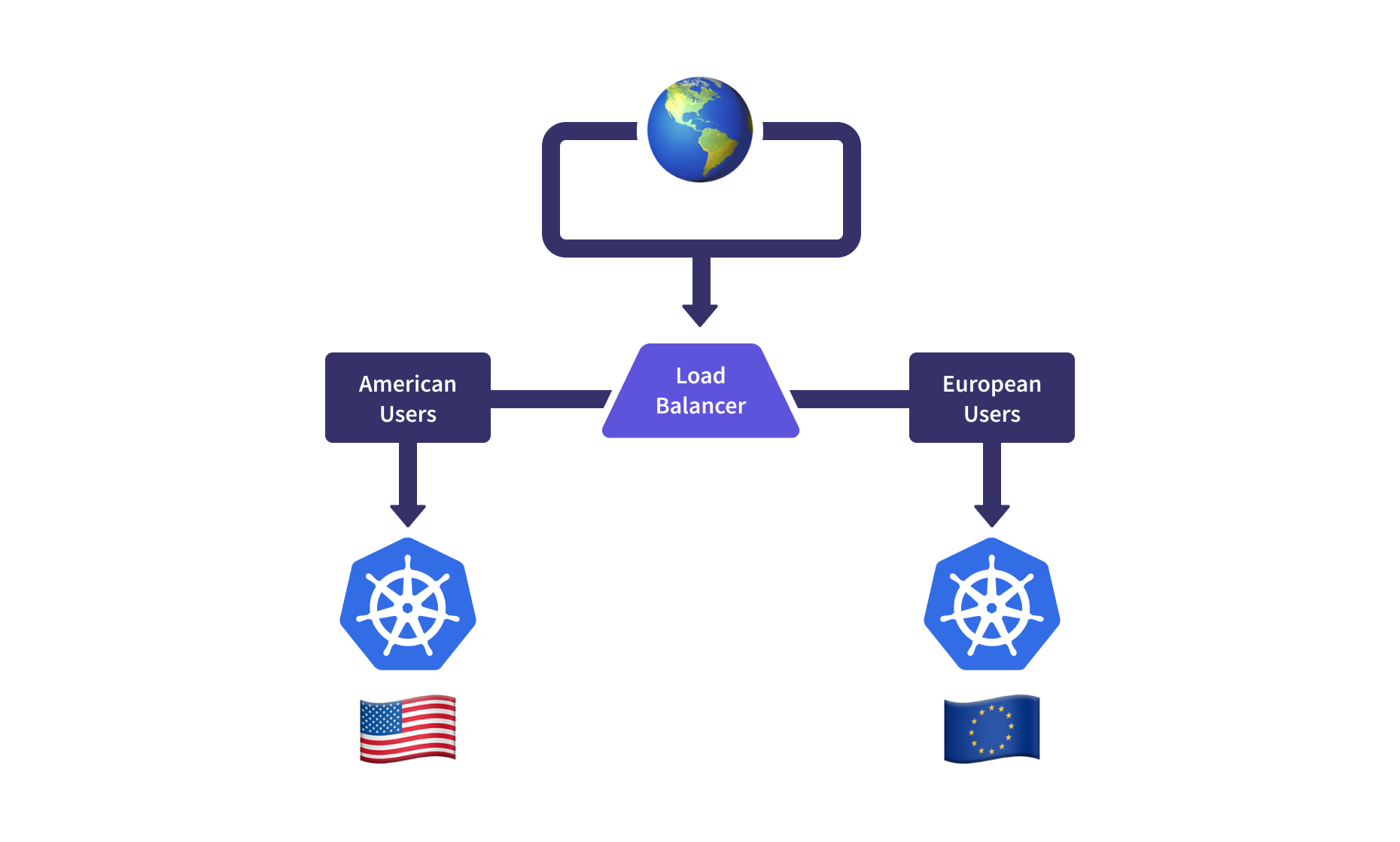
Traffic Management
Fleets also open up avenues for centralized north-south and east-west network traffic configuration options. For N-S ingress, this means routing traffic to the healthiest, geographically closest, or most performant clusters and away from clusters in the midst of upgrades, re-provisioning, or outages. The E-W cluster traffic options, a “multi-cluster service” for example, enable us to deploy applications to a subset of clusters and route traffic internally to the specific clusters serving that component.
Multi-cluster N-S ingress capabilities require the ability to sync status from the set of backend clusters to the central ingress point. This may be controlled manually through an infrastructure provisioning tool or through a central controller if the lifecycle of the router has access to the status in the downstream clusters directly. These load balancers often have health checks that can confirm the health of downstream applications at some basic level, such as a simple HTTP probe.
Qualifying a Fleet
In 2019, Tim Hockin had a great talk at Cloud Native Rejekts called “We’ve Made Quite a Mesh.” This was the time of the emergence of many of the service mesh products and their increasing adoption.
Tim leans into defining what a service mesh is by exploring the core capabilities that comprise popular meshes and comparing them to Kubernetes networking from this perspective, arguing that Kubernetes itself provides many of the required capabilities of a mesh and how you can use this understanding to address broader problems, such as multi-cluster networking.
Let’s take the same approach for understanding this fleet concept.
I want to consider the primary capabilities of the core products in the ecosystem. In this section, I’m going to outline what I think are the most critical aspects, but to be clear, each product has its own take.
Cluster Provisioning
First, there are an excellent set of tools that allow us to provision and manage Kubernetes clusters. kOps, eksctl, and Terraform have all been around for a long time and enabled engineers to provision Kubernetes clusters to their hearts content. Just having “lots of clusters” doesn’t make you a fleet though, let’s shift to the other side of the coin.
In 2018, Chick-fil-A revealed the details of their Kubernetes-cluster-per-store architecture in a great blog post and a number of follow-on talks. That post was recently updated with more captivating details. Being on-prem, their provisioning story differs from those of us operating in the cloud. However, they discuss a tool called Edge Commander which has the capability to issue a wipe against the partition of their nodes which run the Kubernetes control plane while maintaining the persistent data on a separate partition. This is about as fleet as it gets.
ELOTL has a unique approach with their Nova product. Their centralized control plane enables just-in-time provisioning of cloud Kubernetes clusters by cloning existing clusters. Within their product, the entire lifecycle of creation and deletion of a cluster is managed with respect to the workloads that are running (or completed). This is extremely useful for spiky workloads such as large scale ML training or CI/CD workloads.
When you create a cluster resource in Tanzu Mission Control, the product then provisions the necessary resources in your specified cloud account and creates a Tanzu Kubernetes cluster according to your specifications. This product enables you to execute the entire lifecycle of Kubernetes clusters across multiple clouds sourced from a centralized resource.
Application Delivery
Rancher Fleet enables the registration of remote clusters to a central fleet manager cluster. It distributes configurations in a Bundle to matching clusters and reports their status to the central fleet manager. It does not address networking concerns now; the only lifecycle capabilities come from the registration process. The combination of a centralized cluster resource, configuration management, and status reporting makes this a great tool for managing applications across many clusters. Still, it lacks the networking capabilities that differentiate some other fleet products.
ELOTL Nova’s approach to application delivery takes the existing cluster selection capabilities and extends it via its Scheduling Policies. By adapting the concept of spread constraints from Kubernetes pods to the fleet, Nova can ensure that the workload is evenly distributed across the currently available infrastructure.
Chick-fil-A has built similar capabilities for managing application lifecycles from Git repositories. They even call their internal management tool “Fleet”.
Traffic Management
GKE Fleet Manager enables multi-cluster north-south and east-west routing through their Multi Cluster Ingress and Multi-cluster Services. Through Multi Cluster Ingress, you can create external HTTP(S) load balancers that route matching traffic to appropriate target clusters, while syncing with events that occur in the cluster such as pod health checks, a new cluster receiving the deployment, and a cluster being removed from the pool of healthy backends.
One key challenge with global north-south traffic routing is identifying the health of an application on a single cluster. Often, a single readiness probe is insufficient to understand whether the application can successfully respond to requests in a manner that implies that the overall system is healthy.
Within a cloud system, the underlying issues behind increased failure rates in a specific region may not fully bubble up to the cluster status reporting endpoint. This may require some manual or dynamic intervention to detect impacted user experience and shift traffic away when an underlying service has problems.
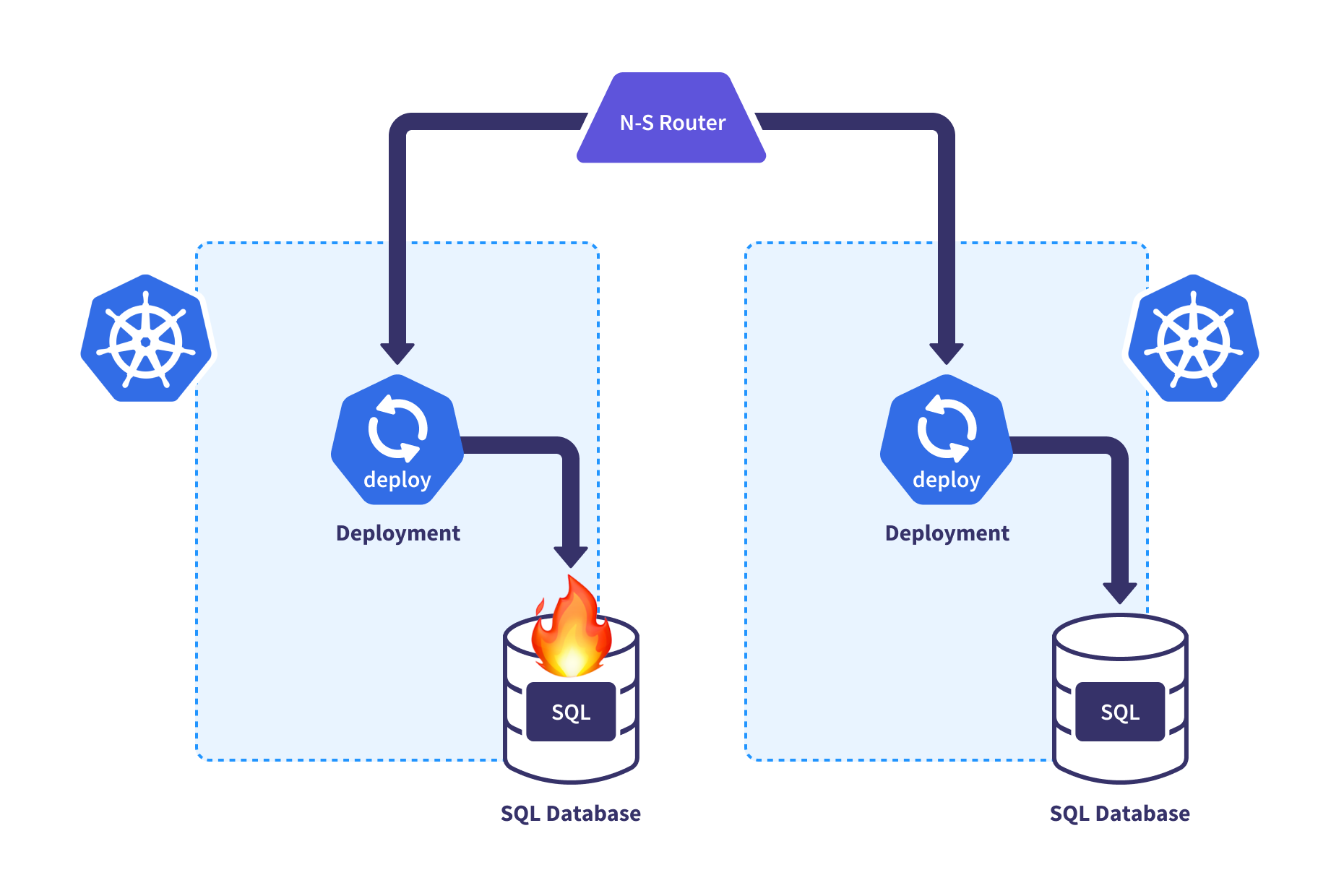
HA/DR Control
Once you have all these application copies across regions or clouds, life isn’t just rainbows and butterflies. When things go wrong, orchestration is required to ensure that failover can occur safely for the application. This centralized control plane can implement all the needed steps to elevate a standby cluster and turn off a cluster where failures are detected.
Ecosystem Evaluation
As you explore solutions to their specific needs and products in this space become more mature, a more formal definition of the concept will emerge. I would argue that centralized multi-cluster configuration management and north-south traffic routing are the most critical capabilities a fleet product can provide end users. I believe products will invest engineering time around these two capabilities to convince organizations to utilize this concept.
Fleets aren’t just a concept in a vacuum, these products exist in the market, with each product focusing on delivering some subset of the capabilities we’ve discussed. Let’s evaluate the product matrix in their current state in February 2023, note that these products are mostly in active development. I’m throwing in the Chick-fil-A fleet capabilities as a nice comparison.
| Centralized Configuration | N-S Routing | E-W Routing | Cluster CRUD | Cluster Status | Multi-Cloud Support | |
|---|---|---|---|---|---|---|
| Rancher Fleet | ✅ | ❌ | ❌ | ❌ | ✅ | ✅ |
| ELOTL Nova | ✅ | ⚠️1 | ⚠️1 | ✅ | ✅ | ✅ |
| GKE Fleet Management4 | ⚠️2 | ✅ | ✅ | ❌ | ✅ 3 | ⚠️3 |
| AKS Fleet Manager | ⚠️5 | ❌ 6 | ✅ | ❌ | ❌ | ❌ |
| Tanzu Mission Control | ⚠️2 | ❌ | ❌ | ✅ | ✅ | ✅ |
| Chick-fil-A Fleet8 | ✅ | ❌ | ❌ | ✅ | ✅ | ❌ |
- Routing capabilities can be added on via external integrations deployed by the central control plane.
- These config management capabilities are more focused on policy/security delivery than application delivery to multiple clusters
- Anthos capability
- As of August 2023, some Anthos capabilities are being moved into the GKE Enterprise product line
- Limited support
- Not yet
- Not a commercially available product
This chart shows that the ecosystem is still maturing its approach to delivering these capabilities and vendors are defining which key capabilities their product will focus on. I expect that we will start to see some unification between the configuration and routing capabilities into a single product category as commercial approaches unify.
Stay Tuned
Our team continues to evaluate this pattern for workloads such as stateless applications, CI/CD on Kubernetes, and distributed cost-efficient machine learning. Subscribe (yes, we still ❤️ RSS) or join our mailing list below for future articles.
What are you doing with your Kubernetes fleet? We’d love to hear! You can reach out to us at https://superorbital.io/contact or send us an email at hello@superorbital.io.